下面介绍一下应用程序来不及处理而导致udp丢包的常见原因:
1、linux内核socket缓冲区设的太小
# cat /proc/sys/net/core/rmem_default
# cat /proc/sys/net/core/rmem_max
可以查看socket缓冲区的缺省值和最大值。
rmem_default和rmem_max设置为多大合适呢?如果服务器的性能压力不大,对处理时延也没有很严格的要求,设置为1M左右即可。如果服务器的性能压力较大,或者对处理时延有很严格的要求,则必须谨慎设置rmem_default 和rmem_max,如果设得过小,会导致丢包,如果设得过大,会出现滚雪球。
2、服务器负载过高,占用了大量cpu资源,无法及时处理linux内核socket缓冲区中的udp数据包,导致丢包。
一般来说,服务器负载过高有两个原因:收到的udp包过多;服务器进程存在性能瓶颈。如果收到的udp包过多,就要考虑扩容了。服务器进程存在性能瓶颈属于性能优化的范畴,这里不作过多讨论。
3、磁盘IO忙
服务器有大量IO操作,会导致进程阻塞,cpu都在等待磁盘IO,不能及时处理内核socket缓冲区中的udp数据包。如果业务本身就是IO密集型的,要考虑在架构上进行优化,合理使用缓存降低磁盘IO。
这里有一个容易忽视的问题:很多服务器都有在本地磁盘记录日志的功能,由于运维误操作导致日志记录的级别过高,或者某些错误突然大量出现,使得往磁盘写日志的IO请求量很大,磁盘IO忙,导致udp丢包。
对于运维误操作,可以加强运营环境的管理,防止出错。如果业务确实需要记录大量的日志,可以使用内存log或者远程log。
4、物理内存不够用,出现swap交换
swap交换本质上也是一种磁盘IO忙,因为比较特殊,容易被忽视,所以单列出来。
只要规划好物理内存的使用,并且合理设置系统参数,可以避免这个问题。
5)磁盘满导致无法IO
没有规划好磁盘的使用,监控不到位,导致磁盘被写满后服务器进程无法IO,处于阻塞状态。最根本的办法是规划好磁盘的使用,防止业务数据或日志文件把磁盘塞满,同时加强监控,例如开发一个通用的工具,当磁盘使用率达到80%时就持续告警,留出充足的反应时间。
处理器:Intel(R) Xeon(R) CPU X3440 @ 2.53GHz,4核,8超线程,千兆以太网卡,8G内存
单机,单线程异步UDP服务,无业务逻辑,只有收包操作,除UDP包头外,一个字节数据。
测试结果
|
进程个数 |
1 |
2 |
4 |
8 |
|
平均处理速度(包/秒) |
791676.1 |
1016197 |
1395040 |
1491744 |
|
网卡流量(Mb/s) |
514.361 |
713.786 |
714.375 |
714.036 |
|
CPU占用情况(%) |
100 |
200 |
325 |
370 |
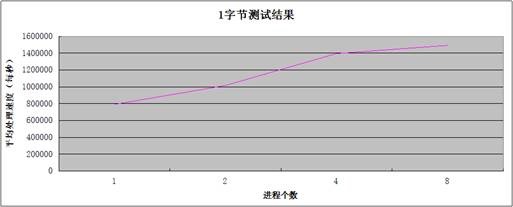

现象:
1、单机UDP收包处理能力可以每秒达到150w左右。
2、处理能力随着进程个数的增加而增强。
3、在处理达到峰值时,CPU资源并未耗尽。
结论:
1、UDP的处理能力还是非常可观的。
2、对于现象2和现象3,可以看出,性能的瓶颈在网卡,而不在CPU,CPU的增加,处理能力的上升,来源于丢包(UDP_ERROR)个数的减少。
 ,我们将会及时处理。
,我们将会及时处理。 | .. 定价:¥45 优惠价:¥42 更多书籍 |
 | .. 定价:¥225 优惠价:¥213 更多书籍 |
